Clostridium botulinum: Difference between revisions
Jump to navigation
Jump to search
No edit summary |
No edit summary |
||
| Line 1: | Line 1: | ||
== Data sources == | == Data sources == | ||
Sanger: | '''Sanger:''' | ||
* [http://www.sanger.ac.uk/Projects/C_botulinum/ Genome Project] | * [http://www.sanger.ac.uk/Projects/C_botulinum/ Genome Project] | ||
| Line 33: | Line 33: | ||
== Assembly == | == Assembly == | ||
'''2007_0725_WGA''' | |||
create a .frg file | create a .frg file | ||
runCA-OBT.pl (default params) | runCA-OBT.pl (default params) | ||
| Line 43: | Line 40: | ||
=> library inser estimates mean=1840.917 stdev=866.039 | => library inser estimates mean=1840.917 stdev=866.039 | ||
'''2007_0801_AMOScmp-relaxed''' | |||
MINCLUSTER=30 , MAXTRIM=50 | MINCLUSTER=30 , MAXTRIM=50 | ||
=> 2 scaffolds, 148 contigs | => 2 scaffolds, 148 contigs | ||
[[Media:CB.2007_0801_AMOScmp-relaxed.qc|CB.qc]] | [[Media:CB.2007_0801_AMOScmp-relaxed.qc|CB.qc]] | ||
| Line 51: | Line 47: | ||
[[Media:CB.2007_0801_AMOScmp-relaxed.plasmid.png|CB.plasmid.png]] | [[Media:CB.2007_0801_AMOScmp-relaxed.plasmid.png|CB.plasmid.png]] | ||
[[Media:CB-scaff.2007_0801_AMOScmp-relaxed.png|CB-scaff.png]] | [[Media:CB-scaff.2007_0801_AMOScmp-relaxed.png|CB-scaff.png]] | ||
'''Location:''' | |||
/fs/szasmg/Bacteria/C_botulinum | |||
Revision as of 13:32, 10 August 2007
Data sources
Sanger:
Hall strain A (ATCC 3502) chromosome: 3,886,916 bp 28.24 GC% plasmid: 16,344 bp 26.80 GC%
Mummerplot: Complete Genome vs Complete Genome
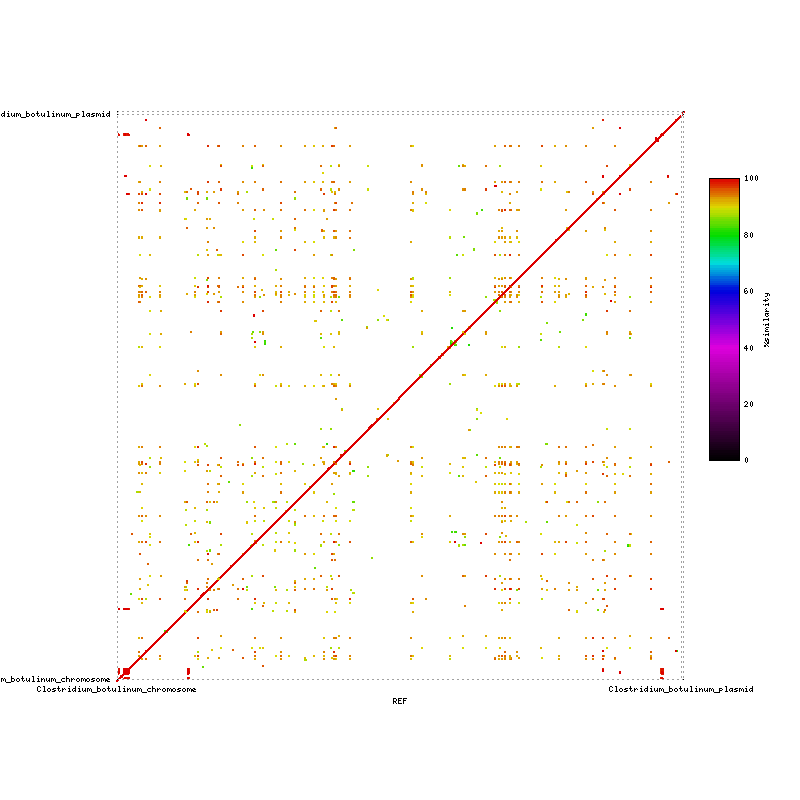{kind=link}
63,115 Sanger reads
Read problems:
no quality : default 20 assigned to all the bases
no mate pairing : can be inferred from names (.p1c, .q1c => 27,331 mates); however there seem to be many errors (links from chromosome to the plasmid)
no library info : assumed there was only one library used
no trimming info : almost all reads have "CONTAINED" alignments to the reference
CLR=1,len(read)
there are 124 regions in the reference which are not covered by reads
NCBI :
Reads have not been submitted to TA
The initial genome assembly was obtained from 69,632 paired end sequences (giving 9.15-fold coverage) derived from four genomic shotgun libraries (all in pUC18 with insert sizes of 1.5–2.0 kb and 2.0–2.2 kb, 2.2–2.5 kb, and 2.5–4.0 kb) using dye terminator chemistry on ABI3700 automated sequencers; 1604 pairedend sequences from one pBACe3.6 library with insert sizes of 15–23 kb (a clone coverage of 3.9-fold) were used as a scaffold. A further 9343 directed sequencing reads were generated during finishing.
Assembly
2007_0725_WGA
create a .frg file runCA-OBT.pl (default params) location: 2007_0725_WGA => 109 scaffolds, 243 contigs => library inser estimates mean=1840.917 stdev=866.039
2007_0801_AMOScmp-relaxed
MINCLUSTER=30 , MAXTRIM=50 => 2 scaffolds, 148 contigs CB.qc CB.chromo.png CB.plasmid.png CB-scaff.png
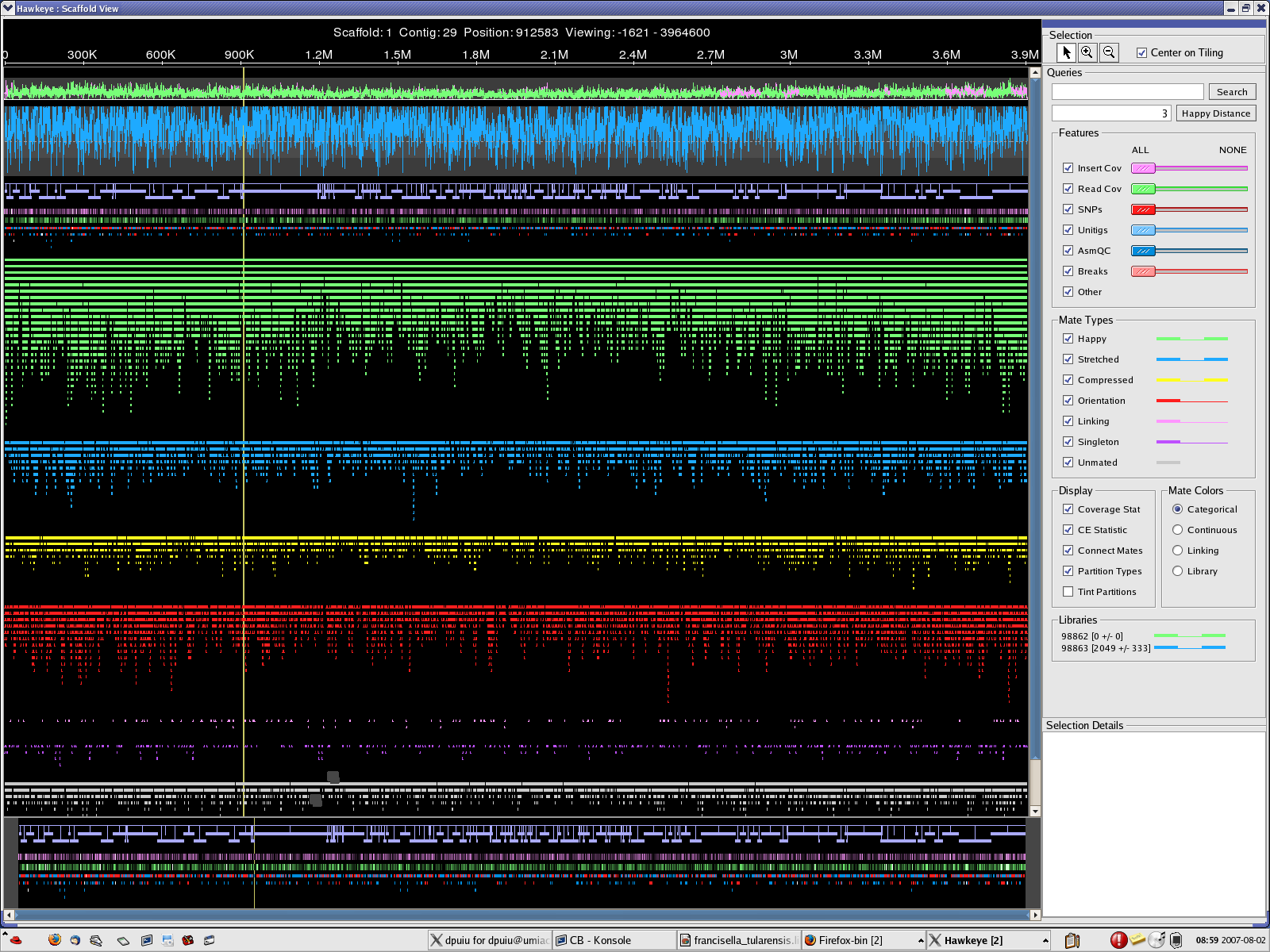{kind=link}
{kind=link}
{kind=link}
Location:
/fs/szasmg/Bacteria/C_botulinum