Bumblebee: Difference between revisions
Jump to navigation
Jump to search
| Line 150: | Line 150: | ||
= Assembly = | = Assembly = | ||
== CA.bog == | == CA.bog s_1 == | ||
* Input : 31*2M s_1 reads trimmed to 100bp & formatted by fastqToCA | * Input : 31*2M s_1 reads trimmed to 100bp & formatted by fastqToCA | ||
| Line 168: | Line 168: | ||
/scratch1/Bombus_impatiens/Assembly/31M | /scratch1/Bombus_impatiens/Assembly/31M | ||
== CA.utg filtered == | == CA.utg s_1,2 filtered == | ||
* Input: 7*2M s_1 & s_2 reads formatted by convert-fasta-to-v2.pl | * Input: 7*2M s_1 & s_2 reads formatted by convert-fasta-to-v2.pl | ||
| Line 202: | Line 202: | ||
/scratch1/Bombus_impatiens/Assembly/14M.redo | /scratch1/Bombus_impatiens/Assembly/14M.redo | ||
== SOAPdenovo | == SOAPdenovo s_3..8 orig (CBCB) == | ||
* Kmer=23 | * Kmer=23 | ||
| Line 213: | Line 213: | ||
gapSeq 49518 28 123 143 181 424 152.97 158 7,574,733 | gapSeq 49518 28 123 143 181 424 152.97 158 7,574,733 | ||
== SOAPdenovo | == SOAPdenovo s_3..8 corr (CBCB) == | ||
* Kmer=31 | * Kmer=31 | ||
| Line 222: | Line 222: | ||
scf 106,217 100 140 434 2418 102317 2,177 7099 23,1261,742 | scf 106,217 100 140 434 2418 102317 2,177 7099 23,1261,742 | ||
== SOAPdenovo | == SOAPdenovo s_3..8 corr (Illinois) == | ||
* Kmer=31 | * Kmer=31 | ||
| Line 232: | Line 232: | ||
ctg 4004102 31 97,618 1916 230,333,709 | ctg 4004102 31 97,618 1916 230,333,709 | ||
ctg100bp+ 120167 100 | ctg100bp+ 120167 100 | ||
== CA s_1..8 corr (CBCB) == | |||
* CA spec | |||
* Location: | |||
ginkgo:/scratch1/Bombus_impatiens/Assembly/CA.s_1-8.cor | |||
Revision as of 09:47, 31 March 2010
Data
- ~ 500B genome
- Complete mitochondrion genomes:
NC_011923.1 15468 14.67 Bombus hypocrita sapporoensis mitochondrion, complete genome NC_010967.1 16434 13.22 Bombus ignitus mitochondrion, complete genome only 88% identity; no rearrangements, only snps, short indels
Traces
- 7 pairs of data files (paired ends) : lanes 1..3,5..8 (lane 4 wasn't used)
Lane Insert ReadLen #Mates #Reads Coverage Comments 1 3K(2..6,avg 4K) 124 34,944,099 14X 865,687(1.2%) reads have qual==0 2 8K(7..9,avg 8K) 124 32,540,640 13X 3 400 124 34,745,750 . gDNA ; originally thought to be 500bp insert instead of 400 5 400 124 34,601,239 . 6 400 124 34,553,857 . 7 400 124 34,682,612 . 8 400 124 12,975,839 . 3-8 151,559,297 303,118,594 75X 1-8 219,044,036 438,088,072 108X
- Adaptors
>circularizarion CGTAATAACTTCGTATAGCATACATTATACGAAGTTATACGA >circularizarion.revcomp TCGTATAACTTCGTATAATGTATGCTATACGAAGTTATTACG >5 GATCGGAAGAGCGGTTCAGCAGGAATGCCGAGATCGGAAGAGCGGTTCAGCAGGAATGCCGAGACCG >3 CGGCATTCCTGCTGAACCGAGATCGGAAGAGCGTCGTGTAGGGAAAGAGTGT
Tasks to figure out
- Erroneous reads/bases, which we need to correct or discard
- GC bias, so we can compute a-stats properly
- Redundancy in the long paired ends, which are lane 1 and lane 2.
- Used the 454 protocol to circularize the DNA for sequencing with the Illumina instrument.
- Some reads will begin in the circularization adaptor and thus will have only one usable read
- Some reads have a few bases of DNA sequence and hit the circularization adaptor right away
- Most reads will have at least 36bp from each end before hitting the adaptor.
- Many reads will not have any adaptor to trim (>125bp of DNA sequence at both ends of the adaptor)
- A small but significant number of reads from the 3kb and 8kb libraries are not recircularized.
- Thus their mate distance is +400bp rather than -3kb or -8kb.
- It's apparently the result of a faulty batch of cre recombinase. This causes problems with contiging and scaffolding.
- It is possible to remove these reads by removing
- mate pairs where neither read is trimmed (thus no adapter ligation may have occurred)
- mate pairs where one read begins with the adapter sequence.
- We are working on this, up to now our paired assembly stages have been disappointing.
- Matt's idea is to exclude all mate pair reads that don't have evidence of the linker with flanking useful sequence, as a way to avoid uncircularized molecules that will give misleading "mate pairs" only 400 bp apart.
- There has been no trimming of the adaptor, which is the 42 base 454 adaptor, so its presence can be used to indicate potentially good mate pairs.
- Even tossing half the mate pairs might not be a problem, as we have perhaps too many anyway.
- But you will also need to toss redundant mate pairs, and that will indeed reduce the total a lot.
- Just to be clear - the 500 base mate pairs should have no such problems, except that as Matt has found from his preliminary assembly, the mean fragment length is actually 400 bp rather than 500 bp (and the 3 and 8 kb PE reads are typically shorter than nominally given, e.g. more like 2.5 and 6 kb).
- You'll also need to throw out all the reads where one of the mates /starts/ with linker, I assume you'd do that anyway. We're also working on ways round this; one might be when we get a better assembly we'll find some better characteristic to filter the unrecircularized reads on.
Trimming
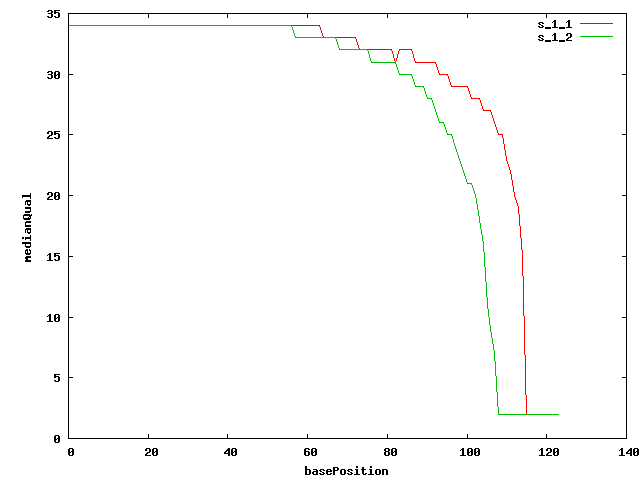{kind=link}
- Quality trimming: trim all bases with fastq quality eq "B" (0)
cat *fastq | ~/bin/fastq2clq.pl
- Adaptor trimming: Align all subsets to adaptors
C CGTAATAACTTCGTATAGCATACATTATACGAAGTTATACGA 3 CGGCATTCCTGCTGAACCGAGATCGGAAGAGCGTCGTGTAGGGAAAGAGTGT 5 GATCGGAAGAGCGGTTCAGCAGGAATGCCGAGATCGGAAGAGCGGTTCAGCAGGAATGCCGAGACCG
id len gc% C 42 30.95 3 52 55.77 5 67 59.70
nucmer -l 8 -c 16 -b 32 -g 32 adaptors.seq ... delta-filter -l 16 -q ... cat *.filter-q.delta | ~/bin/delta2clr53.pl -5 5,3 ...
- Adaptor/primers median positions in the reads
Lib adaptorPos 5'primerPos 3'primerPos s_1 34-75 0-36 0-19 s_2 2-40 0-36 0-19
- Mate stats
Lib #mates adaptor.bothMates adaptor.noMate adaptor.oneMate adaptor.oneMate(filtered) s_1 34944099 269156 9804247 24870696 6048164(17.3%) s_2 32540640 91528 16181288 16267824 1061858( 3.2%) total 67484739 7110022(10.5%)
- Filtered read clr stats
Lib #mates #reads min q1 q2 q3 max mean n50 sum s_1 6048164 12096328 64 80 95 115 124 96.56 101 1,168,064,632 s_2 1061858 2123716 64 80 96 115 124 96.59 101 205,122,226 total 7110022 14220044 64 80 95 115 124 96.57 101 1,373,186,858
- Filtered read GC% stats
Lib #reads min q1 q2 q3 max mean n50 s_1 12096322 0.00 31.93 36.26 42.35 100.00 37.45 38 s_2 2123715 0.00 31.88 36.46 42.48 100.00 37.56 38
- Other frequent kmers
26mer : ACGTTATAACGTATTACGTTATATGG -> revcomp -> CCATATAACGTAATACGTTATAACGT : ~10% of the traces 10mer : AAAAAAAAAA TTTTTTTTTT : ~32% of the traces 53mer: CGATTTCCATGGCGTCGTTTGAGGATTCCAATACGGCGAACCTGTTGTGAGTG : ~2% of the mito seqs (either begin or end); not present in the 2 complete mito's (probably ok)
- Location:
/fs/szattic-asmg4/Bees/Bombus_impatiens/ /fs/szattic-asmg4/Bees/Bombus_impatiens/frg/ # frg files ginkgo:/scratch1/Bombus_impatiens/Data/
D Kelly's trimming
- Reads
. elem min q1 q2 q3 max mean n50 sum s_1_1_sequence.cor.txt 5436814 30 71 90 115 124 89.70 100 487673256 s_1_2_sequence.cor.txt 5864225 30 77 92 110 124 93.27 98 546956864 s_2_1_sequence.cor.txt 1053858 30 80 96 118 124 97.16 102 102395785 s_2_2_sequence.cor.txt 1041846 30 78 93 110 124 93.51 99 97426679 s_3_1_sequence.cor.txt 33668302 30 105 124 124 124 111.04 124 3738530761 s_3_2_sequence.cor.txt 32554322 30 82 108 124 124 100.42 120 3269039697 s_5_1_sequence.cor.txt 33579744 30 109 124 124 124 111.65 124 3749192427 s_5_2_sequence.cor.txt 32465412 30 84 112 124 124 102.13 124 3315553171 s_6_1_sequence.cor.txt 33535725 30 109 124 124 124 111.60 124 3742602285 s_6_2_sequence.cor.txt 32390877 30 83 109 124 124 100.92 123 3268875471 s_7_1_sequence.cor.txt 33674235 30 112 124 124 124 112.19 124 3777917379 s_7_2_sequence.cor.txt 32518568 30 84 110 124 124 101.60 124 3303807321 s_8_1_sequence.cor.txt 11777821 30 113 124 124 124 112.30 124 1322658923 s_8_2_sequence.cor.txt 12176364 30 84 110 124 124 101.51 124 1236034348 total 301,738,113 . . . . . . . 31958664367
- Mates
s_1.mates 5320163 s_2.mates 1034086 s_3.mates 31857304 s_5.mates 31820553 s_6.mates 31748713 s_7.mates 31891468 s_8.mates 11168258 total 144,840,545
- Files
/fs/szattic-asmg4/Bees/Bombus_impatiens/error_free/s_?.frg # frg /fs/szattic-asmg4/Bees/Bombus_impatiens/error_free/s_?_[12]_sequence.cor.txt # fastq
Assembly
CA.bog s_1
- Input : 31*2M s_1 reads trimmed to 100bp & formatted by fastqToCA
- Spec file
unitigger = bog ovlOverlapper = mer obtMerThreshold = 400 ovlMerThreshold = 120 doOverlapTrimming = 0
- Unitigger : max utg len=852bp
- Consensus after unitigger : 3 out of 129 jobs failed
- Location
/scratch1/Bombus_impatiens/Assembly/31M
CA.utg s_1,2 filtered
- Input: 7*2M s_1 & s_2 reads formatted by convert-fasta-to-v2.pl
- Filter:
- only one read from the mate contains the adaptor in the 64..124bp range
- both reads from the mate have good quality in the 0..64bp range
- Spec file
unitigger = utg ovlOverlapper = ovl obtMerThreshold = 400 ovlMerThreshold = 200 doOverlapTrimming = 0 => reads < 64 bp atre trimmed by the gatekeeper; no need to trim
- ovlStore stats
#ovls/read reads min q1 q2 q3 max mean n50 sum 14220044 0 1 5 31 514 31.30 131 445090932
- final stats
. elem min q1 q2 q3 max mean n50 sum ctg 2 1004 1004 1055 1055 1055 1029.50 1055 2059 deg 1433143 64 115 129 164 1028 145.79 145 208938949 assembled 7557472 singletons 6662572
- Mate redundancy
cat 9-terminator/asm.posmap.frgdeg | sort -nk2 -nk3 | perl ~/bin/posmap2ovl.pl | p 'chop $F[1]; chop $F[2]; print "$F[1] $F[2]\n"; print "$F[2] $F[1]\n";' | count.pl -m 2 | more
- Location
/scratch1/Bombus_impatiens/Assembly/14M.redo
SOAPdenovo s_3..8 orig (CBCB)
- Kmer=23
- Input: s_3,5,6,7,8 original reads
- Error correction: no
- Summary
. elem min q1 q2 q3 max mean n50 sum scf 571,114 100 106 115 141 156066 162.19 137 92,628,126 ctg 54049561 24 24 28 42 2049 35.04 35 1,893,660,606 gapSeq 49518 28 123 143 181 424 152.97 158 7,574,733
SOAPdenovo s_3..8 corr (CBCB)
- Kmer=31
- Input: s_3,5,6,7,8 reads
- Error correction: yes
- Summary
elem min q1 q2 q3 max mean n50 sum scf 106,217 100 140 434 2418 102317 2,177 7099 23,1261,742
SOAPdenovo s_3..8 corr (Illinois)
- Kmer=31
- Input: s_3,5,6,7,8 reads
- Error correction: yes; how?
- Summary
. elem min q1 q2 q3 max mean n50 sum scf 17,550 13,460 236,225,169 ctg 4004102 31 97,618 1916 230,333,709 ctg100bp+ 120167 100
CA s_1..8 corr (CBCB)
- CA spec
- Location:
ginkgo:/scratch1/Bombus_impatiens/Assembly/CA.s_1-8.cor