KarshaDASS
Jump to navigation
Jump to search
Karsha is Free Open Source Software that is licensed by the University of Maryland and the Lanka Software Foundation
OUTDATED Karsha: Document Annotation and Semantic Search (DASS)
Karsha DASS is a repository of financial documents that have been annotated using terms from the Financial Industry Business Ontology (FIBO). [Documents can also be annotated using other ontologies and/or thesauri.] We are developing a sample repository comprising a collection of bond prospectus (corporate and municipal bonds) and their supplements retrieved from EMMA [1]
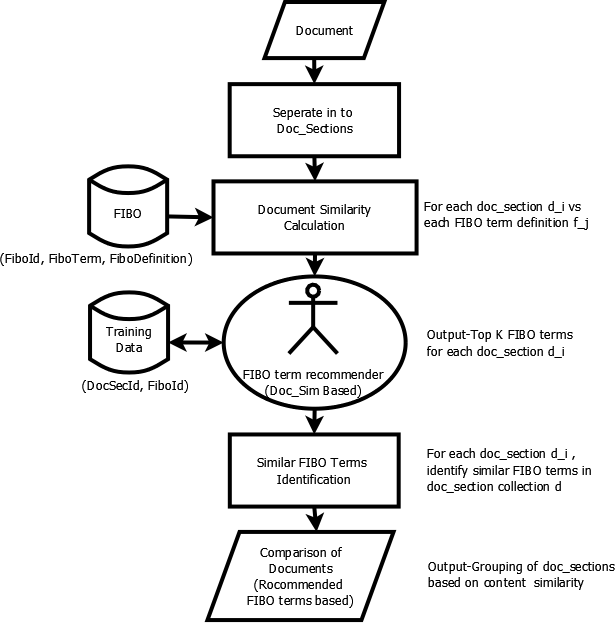
Karsha constructs a Lucene [2] index of sections of the document (indexing the keywords within sentences). It uses Okapi cosine keyword based similarity to compare the sections (sentences) of the document with definitions for ontology terms and chooses/recommends the Top K terms. We focus on the FIBO since it provides an excellent set of definitions.
Potential use cases include the following: - Rank and retrieve documents using FIBO search terms. - Cluster documents to better understand the contents of a repository. - Compare pairs of documents for similarities as well as gaps or dis-similarity. - Karsha can be extended to include sentence understanding so that one can answer more refined questions such as 'which of these instruments is likely to be impacted by a fluctuation of XYZ'?
Architecture and Workflow
Karsha Annotation Architecture Diagram
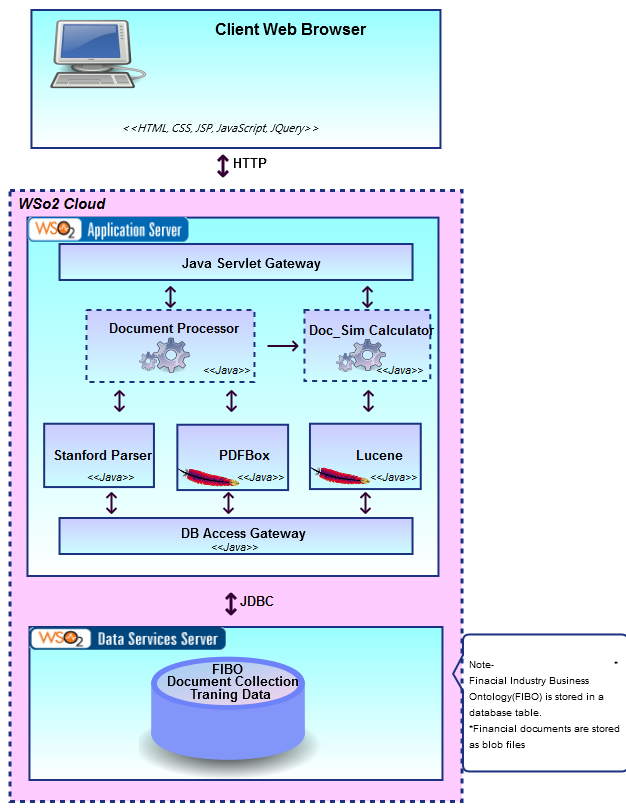 1- Client Web Browser-(Presentation tier)
The presentation layer provides the application’s user interface (UI). The Graphical user interfaces are designed with HTML,CSS, JSP, JavaScript, JQuery technologies for smart and easy user interaction.
2-WSo2 Application Server (Logic tier)
This layer controls the application’s functionality by performing detailed processing and all the processes are running inside the WSo2 cloud.
2.1-Libraries
2.1.1-Apache Lucene
Lucene is an open source full text index and search engine written in Java. The functionalities are mainly used to index PDF document and calculating similarity between documents.
2.1.2-Apache PDFBox
The Apache PDFBox library is an open source Java tool for working with PDF documents. It is used for manipulate PDF documents and to extract content from PDF documents.
2.1.3-Stanford Parser
Stanford parser contains set of open source probabilistic natural language parsers written in Java. It can be used for split sentences, extract named entities, get grammatical structure of sentences. Extracting sentences is the main usage of Stanford Parser in this context.
2.2- Processes
2.2.1-Document Processor
Controlling of text extraction form PDF documents
Processing of text and extraction of sentences
2.2.2-Doc_Sim Calculator
Calculation of similarity between financial documents and FIBO definitions using Okapi Similarity
Recommending FIBO terms for documents based on document similarity values.
3-Data Service Server (Data tier)
Data service server housed inside the WSo2 cloud and having separate server improves scalability and performance. A SQL database has been used for data storage.
Financial Industry Business Ontology is staged in a database table.
Various financial documents are stored as blob files.
1- Client Web Browser-(Presentation tier)
The presentation layer provides the application’s user interface (UI). The Graphical user interfaces are designed with HTML,CSS, JSP, JavaScript, JQuery technologies for smart and easy user interaction.
2-WSo2 Application Server (Logic tier)
This layer controls the application’s functionality by performing detailed processing and all the processes are running inside the WSo2 cloud.
2.1-Libraries
2.1.1-Apache Lucene
Lucene is an open source full text index and search engine written in Java. The functionalities are mainly used to index PDF document and calculating similarity between documents.
2.1.2-Apache PDFBox
The Apache PDFBox library is an open source Java tool for working with PDF documents. It is used for manipulate PDF documents and to extract content from PDF documents.
2.1.3-Stanford Parser
Stanford parser contains set of open source probabilistic natural language parsers written in Java. It can be used for split sentences, extract named entities, get grammatical structure of sentences. Extracting sentences is the main usage of Stanford Parser in this context.
2.2- Processes
2.2.1-Document Processor
Controlling of text extraction form PDF documents
Processing of text and extraction of sentences
2.2.2-Doc_Sim Calculator
Calculation of similarity between financial documents and FIBO definitions using Okapi Similarity
Recommending FIBO terms for documents based on document similarity values.
3-Data Service Server (Data tier)
Data service server housed inside the WSo2 cloud and having separate server improves scalability and performance. A SQL database has been used for data storage.
Financial Industry Business Ontology is staged in a database table.
Various financial documents are stored as blob files.

Karsha Annotation Flowchart

Karsha Annotate Source Code Karsha Source code is released under AGPL license and it's maintained at GitHub repository Pull a copy of source code from here
Karsha Document Annotation and Semantic Search (DASS) Dhananjeyan Balaretnaraja S. Jeyarasan Kasun Perera Amal Siriwardane Louiqa Raschid UMIACS Technical Report, 2012.