|
|
| (2 intermediate revisions by one other user not shown) |
| Line 1: |
Line 1: |
|
| | Long term preservation of digital objects requires systematic methodologies to address the following requirements. |
| A large portion of the scientific, business, cultural, and government digital information being created today needs to be maintained and preserved for future use for periods ranging from a few years to decades and sometimes centuries. For some types of digital information, the use will amount to continuous access and analysis, while for other types, the access will be sporadic starting sometime in the future, possibly running over many decades. The use of the majority of the digital information will fall somewhere in between. It is clear that such data will likely be subjected to substantial "environmental" changes over time, which include going through a large number of technology evolutions, possible changes in stewardships, relocation and repurposing, as well as changes due to systems failures, operational errors, and natural hazards and disasters. The ADAPT project is addressing major components required to build a computing infrastructure to enable long-term digital archiving and preservation, with pilot projects focusing on the preservation of NARA electronic records and geospatial scientific collections.
| |
| Overall Approach
| |
|
| |
|
| The traditional archiving and preservation approach has been a distributed activity in which each organization maintains and preserves its holdings with relatively little sharing (for example, through preservation photocopying). Such an approach is based on well understood and proven processes for archiving and preserving physical holdings. Digital preservation seems to be substantially more complex due, on one hand, to the ease with which digital information can be created and disseminated, and, on the other hand, the fast pace of technology evolution and the fragility of digital information and computing environments. Add to that the security and privacy threats facing digital information connected to the internet.
| | * Each preserved digital object should encapsulate information regarding content, structure, context, provenance, and access to enable the long term maintenance and lifecycle management of the digital object. |
| | * Efficient management of technology evolution, both hardware and software, and the appropriate handling of technology obsolescence (for example, format obsolescence). |
| | * Efficient risk management and disaster recovery mechanisms either from technology degradation and failure, or natural disasters such as fires, floods, and hurricanes, or human-induced operational errors, or security failures and breaches. |
| | * Efficient mechanisms to ensure the authenticity and integrity of content, context, and structure of archived information throughout the preservation period. |
| | * Ability for information discovery and content access and presentation, with an automatic enforcement of authorization and IP rights, throughout the lifecycle of each object. |
| | * Scalability in terms of ingestion rate, capacity and processing power to manage and preserve large scale heterogeneous collections of complex objects, and the speed at which users can discover and retrieve information. |
| | Ability to accommodate possible changes over time in organizational structures and stewardships, relocation, repurposing, and reclassification. |
|
| |
|
| A digital preservation infrastructure must be able to handle the following requirements:
| | Our technology approach is based on a number of premises. The first premise is to encapsulate properties of content, structure, context, presentation, and preservation within a digital object architecture, and enable the infrastructure to manage and preserve these objects. The digital object must contain the essential features that capture what is being preserved, and should include behavioral information about its lifecycle management and preservation. |
|
| |
|
| * Each preserved digital object must contain sufficient information to enable the application of long term preservation policies and to handle its lifecycle management.
| | The second premise of our approach is to separate the management of the digital objects into three levels of abstraction, resulting in a well-defined three-layered architecture. The data layer is responsible for managing the bits representing the digital object across storage systems (possibly evolving through both time and space), while the second layer deals with the semantics of the data and relationships between objects rather storage and bits. The third layer deals with the management of preservation processes and the basic security infrastructure. |
| * Efficient management of technology evolution, both hardware and software, and in particular, the handling of technology obsolescence.
| |
| * Efficient risk management and disaster recovery mechanisms either from technology degradation and failure, or natural disasters such as fires, floods, and earthquakes, or human-induced operational errors.
| |
| * Efficient mechanisms to ensure the authenticity of content, context, and structure of archived information throughout the preservation period.
| |
| * Ability for information discovery and content access and presentation, with an automatic enforcement of authorization and security policies, throughout the lifecycle of each object.
| |
| * Scalability in terms of ingestion rate, capacity, processing power and the speed at which users can discover and retrieve information regarding context.
| |
|
| |
|
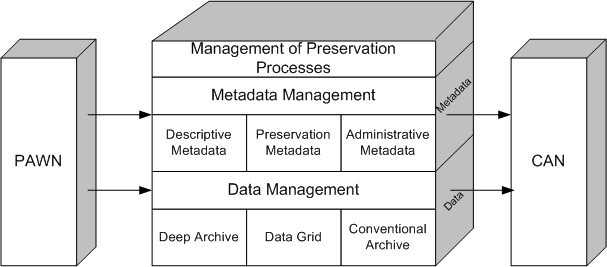
| Our technology approach is based on a number of premises, most of which have been described by other researchers. The first premise is to encapsulate properties of content, structure, context, presentation, and preservation within a digital object architecture, and enable the infrastructure to manage and preserve these objects. The digital object must contain the essential features that capture what is being preserved, and should include behavioral information about its lifecycle management and preservation. Working with the NARA EAP collection and the GLCF collections, we have developed an elaborate object model using and extending METS (Metadata Encoding and Transmission Standards) to encapsulate content, context, structural, descriptive, and preservation metadata into our digital objects. | | Our vision of the overall software architecture necessary to address long term preservation and access is reflected below. |
|
| |
|
| The second premise of the ADAPT architecture is to separate the management of the digital objects into three levels of abstraction, resulting in a well-defined three-layered architecture. The data layer is responsible for managing the bits representing the digital object across storage systems (possibly evolving through both time and space), while the second layer deals with the semantics of the data rather storage and bits. The third layer enables information discovery, search, access, and presentation of the requested digital objects. Such an approach has been advocated through the persistent archives project using the SRB data grid technology. We have further abstracted and refined these layers so that other data grid, peer-to-peer, grid services, or digital library technologies can be easily substituted. In fact, the grid, database, peer-to-peer, and semantic web technologies are fast evolving and hence the need for the abstraction and the clean separation between the layers. In addition, we believe that the data layer should include support for a deep archive to serve as the ultimate recourse for lost data. In this project, we will show how to incorporate an independent deep archive using peer-to-peer technologies.
| | [[Image:Adapt-archive.png]] |
|
| |
|
| The last cornerstone of the ADAPT architecture is that long term digital preservation needs to be organized as a collaborative endeavor to leverage infrastructure support, share resources and knowledge, and develop community-based efforts (such as the effort for setting up a Global Digital Format Registry). In preserving digital assets of interest to significant communities, we advocate a distributed archive infrastructure in which some resources can be combined to enable replication, distributed storage (say, to build a distributed deep archive), or "community-certified" software sharing (such as conversion from one format to another). The involvement of trusted entities will simplify the preservation process and ensure the overall reliable and secure operation of the infrastructure.
| | While our previous work has somewhat focused on the ingestion workflow and bit-level management and preservation, the focus of this proposal is on the more complex issues regarding preservation processes, search, and quantitative evaluations. |
| | |
| Finally, ADAPT borrows considerably from the Open Archival Information System (OAIS) reference framework , including overall terminology. This model seems to be widely accepted; however, as far as we can tell, none of the known prototypes, outside our ingestion software PAWN, seem to capture the core elements of this model adequately.
| |
Long term preservation of digital objects requires systematic methodologies to address the following requirements.
- Each preserved digital object should encapsulate information regarding content, structure, context, provenance, and access to enable the long term maintenance and lifecycle management of the digital object.
- Efficient management of technology evolution, both hardware and software, and the appropriate handling of technology obsolescence (for example, format obsolescence).
- Efficient risk management and disaster recovery mechanisms either from technology degradation and failure, or natural disasters such as fires, floods, and hurricanes, or human-induced operational errors, or security failures and breaches.
- Efficient mechanisms to ensure the authenticity and integrity of content, context, and structure of archived information throughout the preservation period.
- Ability for information discovery and content access and presentation, with an automatic enforcement of authorization and IP rights, throughout the lifecycle of each object.
- Scalability in terms of ingestion rate, capacity and processing power to manage and preserve large scale heterogeneous collections of complex objects, and the speed at which users can discover and retrieve information.
Ability to accommodate possible changes over time in organizational structures and stewardships, relocation, repurposing, and reclassification.
Our technology approach is based on a number of premises. The first premise is to encapsulate properties of content, structure, context, presentation, and preservation within a digital object architecture, and enable the infrastructure to manage and preserve these objects. The digital object must contain the essential features that capture what is being preserved, and should include behavioral information about its lifecycle management and preservation.
The second premise of our approach is to separate the management of the digital objects into three levels of abstraction, resulting in a well-defined three-layered architecture. The data layer is responsible for managing the bits representing the digital object across storage systems (possibly evolving through both time and space), while the second layer deals with the semantics of the data and relationships between objects rather storage and bits. The third layer deals with the management of preservation processes and the basic security infrastructure.
Our vision of the overall software architecture necessary to address long term preservation and access is reflected below.
While our previous work has somewhat focused on the ingestion workflow and bit-level management and preservation, the focus of this proposal is on the more complex issues regarding preservation processes, search, and quantitative evaluations.
